Extend Darwin Gödel machines
How far can we push the Darwin Gödel Machine concept? Let's find out!
Darwin machines apply variation, selection and retention to any problem—just like biological evolution, but for algorithms. Gödel machines rewrite any part of their own code, including their self-improvement logic, but only if they can prove the rewrite improves performance.
Combine them, and you get an AI that evolves better versions of itself through rigorous self-modification.
Short on time? The source is on GitHub.
Reference literature
This project stands on three pillars of research, each worth diving into:
Deep reinforcement learning
If you are new to this space, Unsloth's RL guide and DeepLearning.AI's post-training course provide excellent primers. For deeper implementation details, check out alessiodm's deep RL course.
Evolutionary coding agents
The idea that variation and selection apply to source code just as well as to DNA is not new. AlphaCode performed well in competitive programming, FunSearch discovered new mathematical insights, and AlphaEvolve designs advanced algorithms autonomously.
Darwin Gödel machines (DGM)
The original paper fuses evolution with empirical evaluation. Sakana AI (by the authors) and AI Papers Academy provide a digestible breakdown. Here we borrow the spirit, but skip most of the heavy machinery.
The reinforcement learning question
Could RL be helpful here? Defining a usable policy over code diffs is hard. Discrete code edits (insert, mutate, delete) could work, but they feel cumbersome for higher-level coding patterns. If the policy is another transformer, deep RL approaches like GRPO become feasible.
For this exercise, I opted against fine-tuning a neural network.
Genetic algorithms and multi-agent strategies
How different is evolving a standalone algorithm (like FunSearch and AlphaEvolve) from evolving an agent? Not too different. However, when I pushed this idea to its logical conclusion, unifying the orchestrating agent and the underlying coding agent, it turned into an infinity mirror.
Would it be beneficial to go multi-agent, potentially in a GAN-style fashion? Could the orchestrator figure this out by itself? Early experiments suggest yes, inspired by web search results.
Genetic heuristics also show promise. Instead of only developing linearly as DGM does, we could merge two or more agents. Providing multiple reference agents to the orchestrator achieves this implicitly as part of our generative approach.
Technology choices
Both the orchestrator and the generated agents leverage smolagents primitives.
This is higher-level than most similar efforts—the idea is to gain performance by assembling tool chains, including advanced agentic patterns, and context engineering, not by rewriting fundamental agent blocks.
The orchestrator maintains a weighted reservoir of past agents. Higher benchmark scores increase sampling probability.
It breeds fresh candidates, evaluates them on GSM8K, and repeats this inner loop N times.
Similar to bootstrapping, after N inner iterations, the best coding agent could attempt to improve the orchestrator itself.
We then repeat this process M times. This is not implemented yet.
Results and insights
The first run was intentionally minimal: N = 20, M = 0, 20 questions sampled from GSM8K only.
At this scale, noise is a big factor.
Still, the score distribution tells a compelling story.
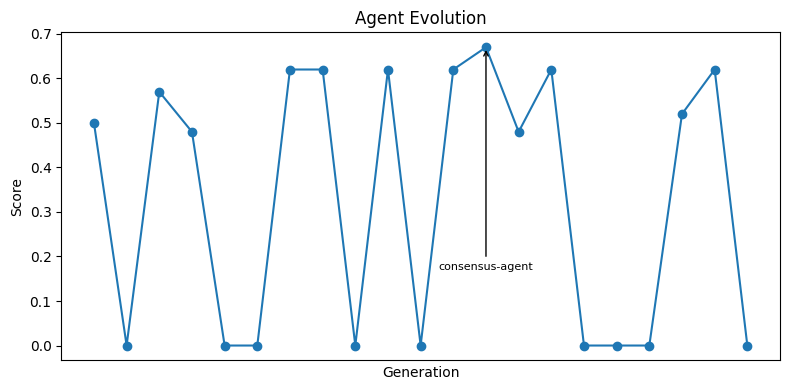
Many candidates flatline at zero. Often because the orchestrator hallucinates smolagents kwargs or dynamic tool (collection) names that cannot be caught statically.
The current top performer is a team of three agents where two produce answers and a third finds consensus. If no consensus emerges, it goes with the "superior" answer based on confidence scores.
Often generated strategies involved:
- Specialized agents focused on single tools (e.g., web search only)
- Critic agents that add reflection rounds before answering
- Custom tooling that extends beyond the base smolagents toolkit
Looking at the results, my hunch is the next generation to outperform the consensus-agent would be a merger of the consensus approach with the critic pattern. The latter scores slightly below the consensus-agent but consistently high and complements it well.
For now, it seems better-performing agents are essentially brute-forcing solutions by answering or reviewing the same question multiple times. It improves benchmark scores, at the cost of burning a lot more tokens per question answered.
A next step could be multi-objective optimization that incorporates algorithm length, average token consumption, and execution time. This should ensure that elegant solutions beat brute force.