Gemini Diffusion
First impressions
I just got access to Gemini Diffusion. The speed is mind-blowing. From what I can tell, the model diffuses blocks of text sequentially—about two paragraphs per block. Each finished block is fed back in as context for the next one.
I tried it on a handful of tasks:
- Planning an event
- Coding a small app
- Solving a LeetCode-style interview question
- Summarization of a long document
- Question-and-answer with provided context (car rental agreement)
- Writing a long essay
- Generating a Markdown table
Formatting can be a bit messy, and you sometimes get repetition between neighboring paragraphs. It also struggles to surface some of the relevant nuggets of information when the user prompt is huge (e.g. the car rental agreement). Still, overall performance is quite impressive.
Riddle and Chain-of-Thought
I also tried to get the model to solve a riddle.
It got it wrong.
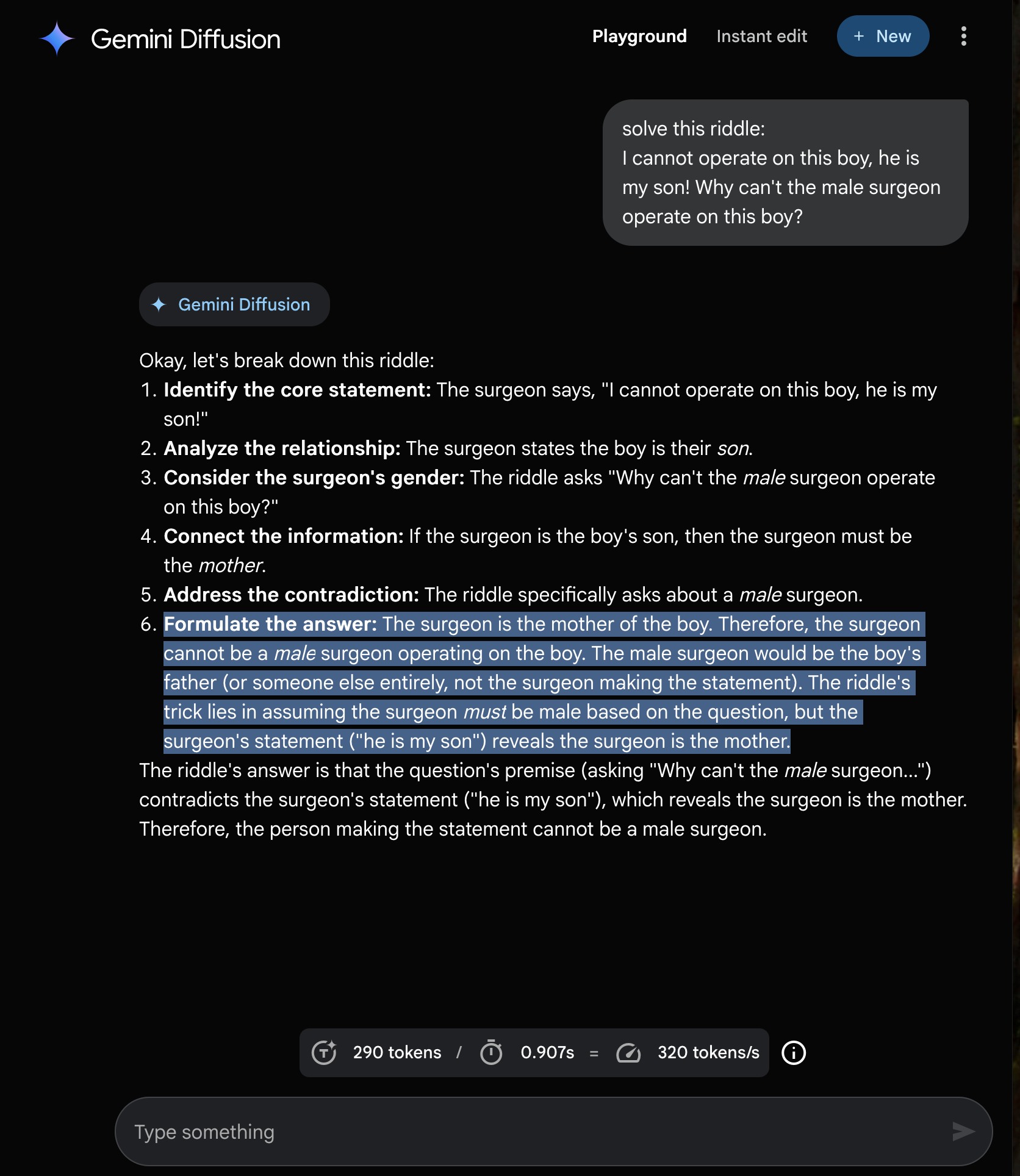 My next thought was to try Chain-of-Thought (CoT) prompting.
Two things happened:
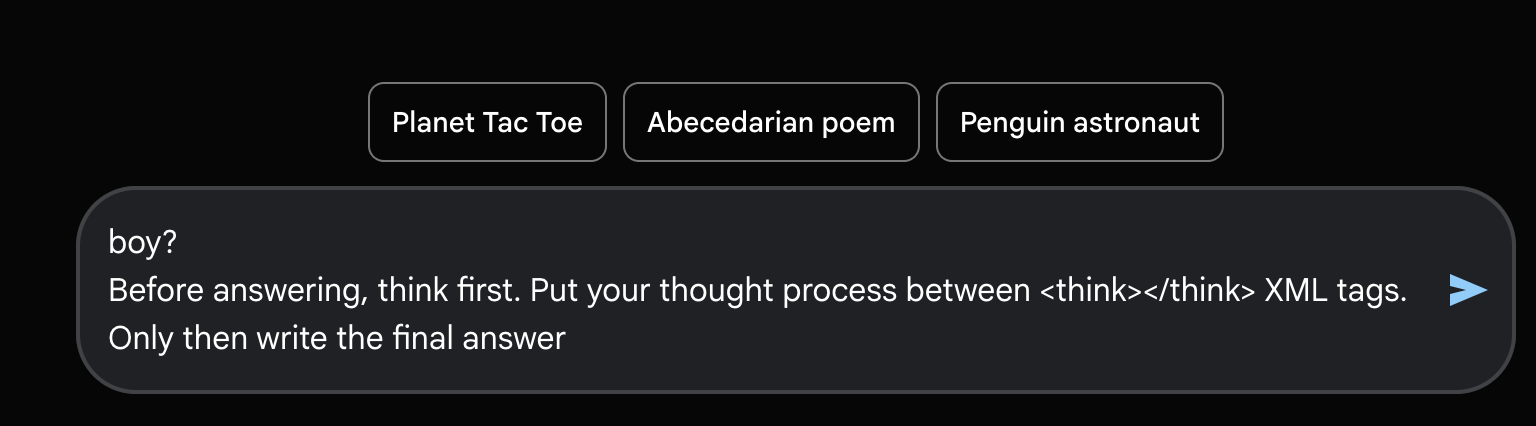
My next thought was to try Chain-of-Thought (CoT) prompting.
Two things happened:
- The
<think>tags were removed from the prompt. - The model kept generating tokens until it hit roughly 2^14 tokens, then displayed nothing.
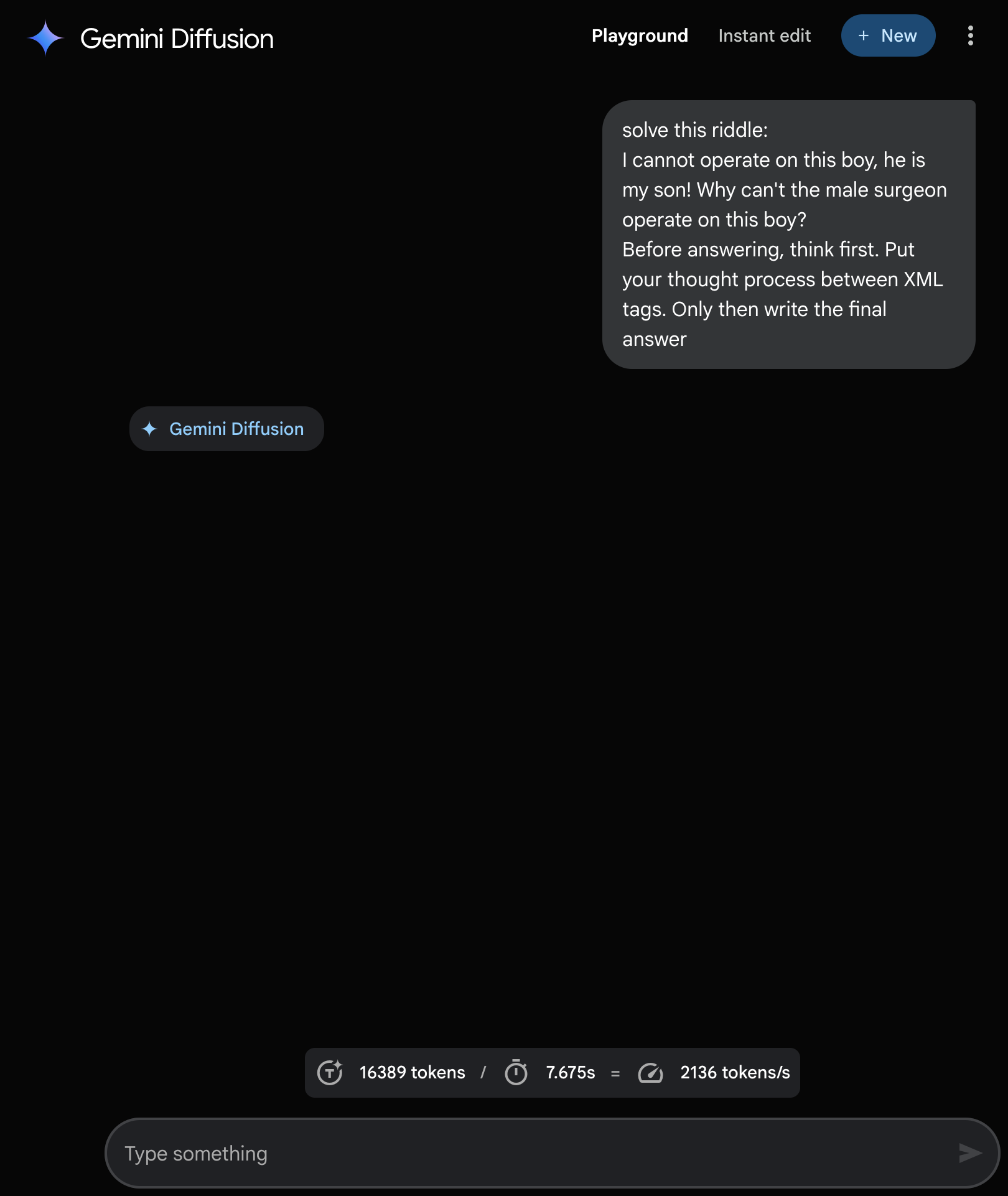
Questions and thoughts
- Image generation is edging towards auto-regressive methods (4o Image Generation), just when diffusion-based text generation becomes practical.
- How will inference-time reasoning work? And is the above CoT failure a sign it is already doing some reasoning behind the scenes? In a diffusion world, I imagine you generate thinking text first, potentially with a couple of refinement rounds, then feed it back in to diffuse the first and subsequent response blocks.
- Will users mind that it does not stream the text? You could always fake streaming by chunking the output.
- Could we mix auto-regressive and diffusion approaches for text the same way we already blend them for images?